Das frei für Mac OS X verfügbare Optimierungswerkzeug komprimiert Bilder verlustfrei, ohne die Pixel zu verändern, und reduziert damit den Platzbedarf von Bilddateien.
Wenn man „Speichern fürs Web“ (z.B. in Adobe Illustrator oder Adobe Photoshop) als Standard-Methode zum Erzeugen optimierter Web-Bilder benutzt, geht man davon aus, dass dabei das Beste an Optmierung aus dem Bild herausgeholt wird.
Beispielbild für die Optimierung
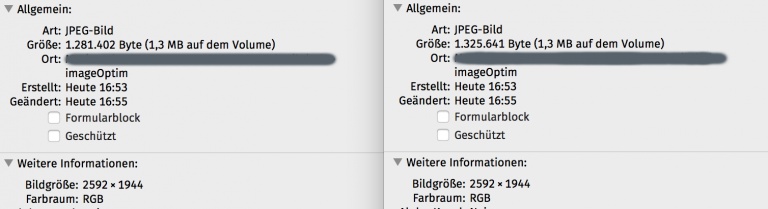
Größenvergleich: Rechts JPG in Originalgröße vom Tablet in Photoshop mit Speichern fürs Web und 60% Qualität gespeichert, Links das Bild nach der Optimierung.
Optimierungsergebnis im JPG-Format
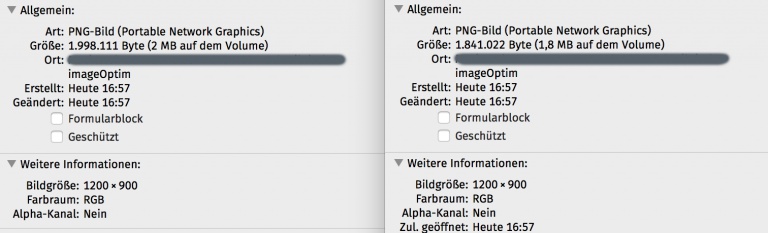
Die PNG-Variante mit einer kompakteren Größe. Links das Originalbild mit einer Größe von 1200×900 Pixeln als PNG24 gespeichert. Rechts die optimierte Variante.
Optimierungsergebnis im PNG-Format
ImageOptim kriegt diese Dateien aber nochmals kleiner. Zum Optimieren zieht man einfach das Bild/ die Bilder auf das Programmfenster, welches die Dateien einfach am gleichen Platz wieder speichert. Es entsteht also nicht wirklich ein zusätzlicher Arbeitsaufwand.
Nach fast einem Jahr der Beta-Phase ist die neue Websites der britischen Zeitung „The Guardian“ am 28. Januar 2015 offiziell zur einzigen Website geworden
Im letzten Jahr bin ich mehrfach auf dieses Projekt gestoßen worden – nicht zuletzt durch Oliver Reichensteins Vortrag bei der beyondtellerrand in Berlin.
Aus Entwicklersicht birgt dieses Projekt viele spannende Aspekte, schon wegen der Bekanntheit der Site, wegen ihres Umfangs, weil der Relaunch mit einem internen Team durchgezogen wurde usw.
Interessant auch, dass sie einen anderen Ansatz zum Aufbau von Websites wählt. Weg vom Denken in „Bäumen“ und Hierarchien, hin zu einer flexiblen, flachen Struktur – näher an die Realität des Surfverhaltens. Geteilter Content, z.B. über Twitter, ist ja immer ein Direktlink auf Einzelseiten. Jede Seite wird damit zur Startseite: „Every article should be a homepage“.
Dieses Ziel wird durch den Seitenaufbau mit Hilfe von Containern umgesetzt. Ich will versuchen, das zu erklären: Eine Website wird linear aus Seitenabschnitten zusammengesetzt, die von links nach rechts die gesamte Seitenbreite füllen. Diese Seitenabschnitte sind aber nicht einfach „Textabschnitt“, „Bild“, „Werbeblock“, „Video“, sondern können in sich komplexe Inhalte oder Funktionen enthalten. Wichtig dabei ist – so wie ich das verstanden habe, dass Inhalt und Funktionalität eines Containers zusammengehören. Der Hintergedanke wird sofort deutlich, wenn man an responsive Websites denkt. Bei einer Spaltenstruktur (die genau aus diesem Grund seltener wird) hat man ja das Problem, dass in der linearen Umsetzung beispielsweise erst der Inhalt (ein Artikel) und dann später, ganz weit unten, zusätzliche „Rand“-informationen kommen, die auf einem breiten Display nebeneinander stehen würden. Im Containermodell wird versucht, diese räumliche Nähe der Inhalte beizubehalten.
Wie so viele Sachen hört sich das erstmal nicht sehr spektakulär an, in der Konsequenz der Umsetzung macht es dann aber doch einen Unterschied. Ich stelle mir vor, dass dieser Grundgedanke die Redakteure vom festen Gerüst des Template-Denkens befreit und dazu zwingt, sich jeweils passende Zusammenstellungen von Inhalten und Teaser und anderen Elementen zu überlegen.
Das führt mich dann auch zum nächsten interessanten Punkt an diesem Projekt: Spezielle Aufgaben bedürfen spezieller Werkzeuge. Für die Guardian-Website wurde eigens ein CMS entwickelt, welches dann sicherlich diesen Workflow und das Layoutmodell nahtlos unterstützt. Zum Back-End habe ich bis auf einen Mini-Screenshot in [3] keine Bilder gefunden. Im Entwickler-Blog [1] findet man dagegen Infos zum verwendeten Editor scribe, der ebenfalls für dieses Projekt entwickelt wurde.
Die neue Website wurde von einem hausinternen Team entwickelt, welches sich für Workshops externe Kollegen dazuholte. „As part of our product discovery process the team ran several ideation workshops with colleagues in editorial and commercial, as well as involving Information Architects, a design agency with experience in digital news. It was during these workshops with Oliver Reichenstein and Konstantin Weiss of iA where the concept of containers and the container model really came to life.“ [2]
Montage von vier zufällig gewählten Artikelseiten des Guardian
Ich bin gespannt, wie sich die Website im Laufe der Zeit weiterentwickelt. Wenn ich mal vier zufällig aus verschiedenen Ressorts herausgepickte Artikelseiten vergleiche, dann sehe ich schon, dass es natürlich ein Repertoire an mehr oder weniger festen Blöcken gibt, die immer wieder – auch in ähnlicher Anordnung – benutzt werden. Ich nehme an, die Leser sollen auch nicht durch zu viel Vielfalt verunsichert werden.
Auf twitter wurde ich heute morgen darüber informiert, dass am Wochenende der Open Data Day stattgefunden hat (21. Februar).
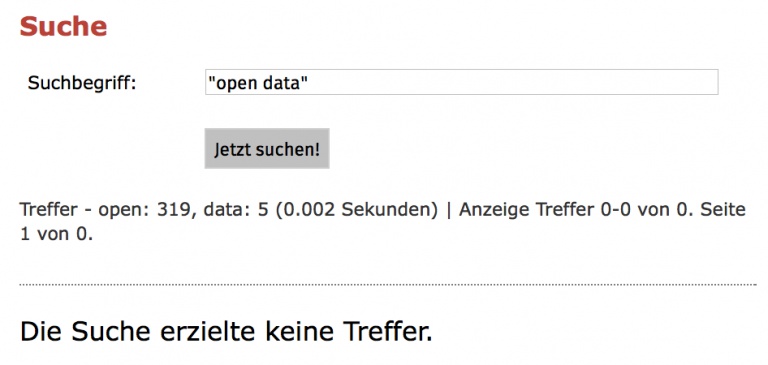
Keine Ergebnisse für „open data“ in Weimar? • Bildschirmfoto der Suchseite auf weimar.de mit Suchbegriff „open data“ am 23.02.2015 (Ausschnitt)
Bei Open Data geht es darum, Daten, die in öffentlichen Verwaltungen anfallen – also Daten, die meist auf Basis der Einwohner oder Firmen einer Gemeinde, Region oder eines Landes generiert werden – diesen Einwohnern als öffentliches Gut in Rohform, maschinenlesbar zur Verfügung zu stellen; ausführliche Erläuterungen zu Open Data bei Wikipedia.
Auf Events, wie dem Open Data Day (Liste der Events in Deutschland), treffen sich Entwickler (auch Grafiker und Journalisten?), um mit diesen Daten zu arbeiten und daraus nützliche Anwendungen, Karten oder Infografiken zu entwickeln.
Die einzelnen Datenverwalter (Besitzer/Inhaber wären hier die falschen Worte) gehen regional sehr unterschiedlich mit der Bereitstellung dieser Daten um.
Städte wie Berlin (http://daten.berlin.de) oder Hamburg (http://transparenz.hamburg.de/open-data/) haben eigene Open-Data-Portale, in denen man nach Datensätzen recherchieren kann. Auch für den Bund gibt es ein Portal (https://www.govdata.de) für den „einheitlichen, zentralen Zugang zu Verwaltungsdaten aus Bund, Ländern und Kommunen“. Der Verein Open Knowledge Foundation Deutschland betreibt zudem das Portal https://offenedaten.de.
Die Suche nach offenen Datensätzen für Weimar dagegen bleibt erfolglos. Jena, sogar mit einem eigenen Event beim Open Data Day vertreten http://de.opendataday.org/jena/, scheint in diesem Punkt etwas offener zu sein.
Falls ich die versteckten Links nur nicht gefunden habe, bitte ich um die entsprechenden Hinweise in den Kommentaren.
Für nächstes Jahr steht der Termin schon in meinem Kalender. Ich bin gespannt, was sich bis dahin getan haben wird. Open Data wird sicher auch ein Thema an einem der nächsten Webmontage sein.
Freunde von Musik, Infografik und Naturwissenschaft werden an desem Artikel gleichermaßen ihre Freude haben. Es gab schon 2011 mal einen Blogartikel mit dem Titel The History of Joy Division’s “Unknown Pleasures” Album Art, in welchem Adam Capriola schon auf der richtigen Spur war.
Ich vermeide es nun, tiefer ins Detail zu gehen, empfehle die verlinkten Artikel mit spannendem Bildmaterial und lausche statt dessen der Musik:
Schon wieder den Spickzettel auf dem Schreibtisch nicht gefunden oder unterwegs nicht dabei?
Sonderzeichenhilfe „Liebe Mac-Tastatur“
Die Sonderzeichen-Hilfe gibt es jetzt als Website von Viktor und Clemens Nübel. Für die Sonderzeichen selbst lassen sich die Tastaturkombinationen für Mac, Windows und Linux sowie dne/die/das HTML-Entity anzeigen. Neben diesem „praktischen“ Nutzen ist die Website aber auch eine Demo-Seite für fünf Schriftentwürfe von Viktor Nübel.
Große Ereignisse werfen ihre Schatten voraus … Die Stadt Weimar hat am 20. Januar 2015 den Rahmenterminplan zum Bau des Bauhaus-Museums in Weimar auf twitter gepostet:
Vom Typus der Infografik her, haben wir es hier mit einem Gantt-Diagramm (siehe Wikipedia) zu tun, welches – wie im vorliegenden Beispiel – gerne mit Excel simuliert wird.
Ich nehme an, dass ein beträchtlicher Anteil der Verzögerungen auf Großbaustellen auf die armen MitarbeiterInnen zurückzuführen ist, die mühevoll in Handarbeit solche Excel-Zeitpläne aktualisieren müssen.
Aus (fast) nachbarschaftlicher Sicht auf den Standort dürfen wir uns laut Plan schon im November diesen Jahres auf den ersten Spatenstich freuen.